Las medidas de tendencia central en la estadistica descriptiva son medidas de tendencia estadistica que pretenden resumir en un solo costo a un grupo de valores. Representan un centro alrededor del cual está localizado el grupo de los datos. Las medidas de tendencia central más usadas son: media, mediana y moda. Las medidas de dispersión sin embargo miden el nivel de dispersión de los valores de la variable. Dicho es decir las medidas de dispersión pretenden evaluar en qué medida los datos difieren entre sí. Así, los dos tipos de medidas utilizadas en grupo permiten explicar un grupo de datos entregando datos acerca de su postura y su dispersión.
Los métodos para obtener las medidas de tendencia central estadísticas difieren levemente dependiendo de la manera en que estén los datos. Si los datos se hallan ordenados en una tabla estadística mencionaremos que se hallan “agrupados” y si los datos no permanecen en una tabla hablaremos de datos “no agrupados”.
Según este criterio, haremos primero el análisis de las medidas estadísticas para datos no agrupados y después para datos agrupados.
Medidas de tendencia central estadísticas en datos no agrupados
Media
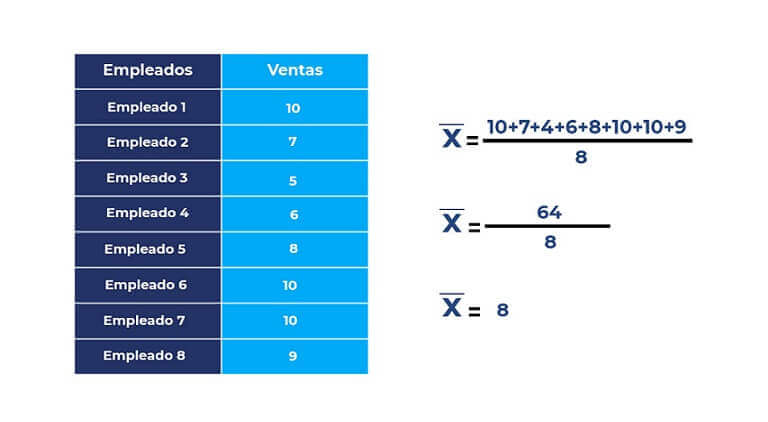
El tamaño de tendencia central más notoria y usada es la media aritmética o promedio aritmético. Se representa por la letra griega µ una vez que se trata del promedio del mundo o población y por Ȳ (léase Y barra) una vez que se trata del promedio de la muestra. Es fundamental resaltar que µ es una porción fija en lo que el promedio de la muestra es variable pues diferentes muestras extraídas de la misma población tienden a tener diferentes medias. La media se expresa en la misma unidad que los datos originales: cm, horas, gramos, etcétera.
Si una muestra tiene 4 visualizaciones: 3, 5, 2 y 2, por definición el estadígrafo va a ser:
Estos cálculos tienen la posibilidad de simbolizar:
Donde Y1 es el costo de la variable en la primera observación, Y2 es el costo de la segunda observación y de esta forma sucesivamente. Generalmente, con “n” visualizaciones, Yi representa el costo de la i-ésima observación. En esta situación el promedio está dado por
De aquí se desprende la fórmula definitiva del promedio:
Desviaciones: Se define como la desviación de un dato a la diferencia entre el costo del dato y la media:
Ejemplo de desviaciones:
Una propiedad interesante de la media aritmética es que la suma de las desviaciones es cero.
Mediana
Otra medida de tendencia central es la mediana. La mediana es el costo de la variable que ocupa la postura central, una vez que los datos se disponen en orden de intensidad. O sea, el 50% de las visualizaciones tiene valores equivalentes o inferiores a la mediana y el otro 50% tiene valores equivalentes o mejores a la mediana.
Si el número de visualizaciones es par, la mediana corresponde al promedio de ambos valores centrales. Ejemplificando, en la muestra 3, 9, 11, 15, la mediana es (9+11)/2=10.
Moda
La moda de una repartición se define como el costo de la variable que más se repite. En un polígono de frecuencia la moda corresponde al costo de la variable que está bajo el punto máximo del gráfico. Una muestra puede tener bastante más de una moda.
Medidas de dispersión
Las medidas de dispersión entregan datos sobre la alteración de la variable. Pretenden resumir en un solo costo la dispersión que tiene un grupo de datos. Las medidas de dispersión más usadas son: Rango de alteración, Varianza, Desviación estándar, Coeficiente de alteración.
Rango de Variación
Se define como la diferencia entre el más grande costo de la variable y el menor costo de la variable.
La mejor medida de dispersión, y la más generalizada es la varianza, o su raíz cuadrada, la desviación estándar. La varianza se representa con el signo σ² (sigma cuadrado) para el mundo o población y con el signo s2 (s cuadrado), una vez que hablamos de la muestra. La desviación estándar, que es la raíz cuadrada de la varianza, se representa por σ (sigma) una vez que pertenece al cosmos o población y por “s”, una vez que forma parte de la muestra. σ² y σ son límites, constantes para una población especial; s2 y s son estadígrafos, valores que cambian de muestra en muestra en una misma población. La varianza se expresa en unidades de variable al cuadrado y la desviación estándar sencillamente en unidades de variable.
Fórmulas
Donde µ es el promedio poblacional.
Donde Ȳ es el promedio de la muestra.
Consideremos en forma de ejemplo una muestra de 4 visualizaciones
De acuerdo con la fórmula el promedio calculado es 7, veamos ahora el cálculo de las medidas de dispersión:
s2 = 34 / 3 = 11,33 Varianza de la muestra
La desviación estándar de la muestra (s) va a ser la raíz cuadrada de 11,33 = 3,4.
Interpretación de la varianza (válida además para la desviación estándar): un elevado costo de la varianza sugiere que los datos permanecen alejados del promedio. Es complicado hacer una interpretación de la varianza teniendo un solo costo de ella. El caso es más clara si se comparan las varianzas de 2 muestras, ejemplificando varianza de la muestra igual 18 y varianza de la muestra b igual 25. En esta situación mencionaremos que los datos de la muestra b poseen más grande dispersión que los datos de la muestra a. esto quiere decir que en la muestra a los datos permanecen más cerca del promedio y sin embargo en la muestra b los datos permanecen más alejados del promedio.
Coeficiente de Variación
Es una medida de la dispersión relativa de los datos. Se define como la desviación estándar de la muestra expresada como porcentaje de la media muestral.
Es de especial utilidad para equiparar la dispersión entre cambiantes con diversas unidades de medida. Esto pues el coeficiente de alteración, a diferencia de la desviación estándar, es sin dependencia de la unidad de medida de la variable de análisis.
Medidas de tendencia central y de dispersión en datos agrupados
Se identifica como datos agrupados a los datos dispuestos en una repartición de frecuencia. En tal caso las fórmulas para el cálculo de promedio, mediana, modo, varianza y desviación estándar tienen que integrar una leve modificación. En seguida se entregan los detalles para todas las medidas.
Promedio en datos agrupados
La fórmula es la siguiente:
Donde ni representa todas las frecuencias que corresponden a los diferentes valores de Yi.
Consideremos como ejemplo una repartición de frecuencia de madres que asisten a un programa de lactación materna, clasificadas conforme el número de partos. Por tratarse de una variable en escala discreta, las clases o categorías asumen solamente ciertos valores: 1, 2, 3, 4, 5.
Entonces las 42 madres tuvieron, aproximadamente, 2,78 partos.
Si la variable de interés es de tipo constante va a ser primordial establecer, para cada intervalo, un costo medio que lo represente. Este costo se denomina marca de clase (Yc) y se calcula dividiendo por 2 la suma de los parámetros reales del intervalo de clase. De allí en adelante se nace igualmente que en el ejercicio anterior, reemplazando, en la formula de promedio, Yi por Yc.
Mediana en datos agrupados
Si la variable es de tipo discreto la mediana va a ser el costo de la variable que corresponda a la frecuencia acumulada que supere velozmente a n/2. En los datos de la tabla 1 Me=3, debido a que 42/2 es igual a 21 y la frecuencia acumulada que supera rápidamente a 21 es 33, correspondiente a un costo de variable (Yi) igual a 3.
Si la variable es de tipo constante se necesita, primero, detectar la frecuencia acumulada que supere en forma rápida a n/2, y después utilizar la siguiente fórmula:
Donde:
Moda en datos agrupados
Si la variable es de tipo discreto la moda o modo va a ser al costo de la variable (Yi) que tenga la más grande frecuencia absoluta ( ). En los datos de la tabla 1 el costo de la moda es 3 debido a que este costo de variable corresponde a la más grande frecuencia absoluta =16.
Posteriormente se muestra un caso muestra incluido para promedio, mediana, varianza y desviación estándar en datos agrupados con intervalos.
Varianza en datos agrupados
Para el cálculo de varianza en datos agrupados se usa la fórmula
Con los datos del ejemplo y rememorando que el promedio (Y) terminó ser 2,78 partos por mamá,
Una vez que los datos permanecen agrupados en intervalos de clase, se labora con la marca de clase (Yc), de tal modo que la fórmula queda:
Donde Yc es el punto medio del intervalo y se denomina marca de clase del intervalo
Yc= (Límite inferior del intervalo + limite preeminente del intervalo)/2.
Percentiles
Los percentiles son valores de la variable que dividen el reparto en 100 piezas equivalentes. De esta modalidad si el percentil 80 (P80) es igual a 35 años de edad, supone que el 80% de los casos tiene edad igual o inferior a 35 años.
Su método de cálculo es subjetivamente sencilla en datos agrupados sin intervalos.
Retomemos el ejemplo de la variable número de partos:
El percentil j (Pj) corresponde al costo de la variable (Yi ) cuya frecuencia acumulada supera velozmente al “j” % de los casos (jxn/100).
El percentil 80, en los datos de la tabla, va a ser el costo de la variable cuyo Ni sea rápidamente mayor a 33,6 ((80×42) /100).
El primer Ni que supera a 33,6 es 39. Por consiguiente al percentil 80 le corresponde el costo 4. Se cuenta entonces que el percentil 80 es 4 partos (P80=4). Este resultado supone que un 80% de las madres estudiadas tuvieron 4 partos o menos.
Si los datos permanecen agrupados en una tabla con intervalos, el método es levemente más difícil debido a que se hace elemental la aplicación de una fórmula.
Se aplica a los datos del intervalo cuya frecuencia acumulada (Ni) sea rápidamente preeminente al “j” % de los casos (jxn/100).
En la siguiente tabla se muestra el reparto de 40 familias según su ingreso mensual en una cantidad enorme de pesos. Nótese que para calcular el centro de clase se utilizaron los parámetros reales de cada intervalo.
Ventajas y desventajas del rango en estadistica
Definición de percentiles estadistica
Ejemplos de calculo de cuartiles
¿Qué es media movil?

Ejercicios resueltos de mediana estadistica

Ejercicios resueltos de media estadistica

3 interesantes ejemplos de la Media
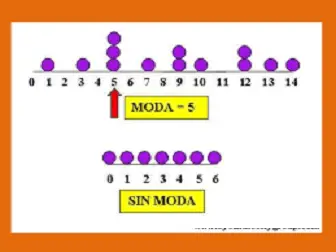
3 interesantes ejemplos de moda